论文阅读-FuseAD: Unsupervised Anomaly Detection in Streaming Sensors Data by Fusing Statistical and Deep Learning Models
FuseAD: Unsupervised Anomaly Detection in Streaming Sensors Data by Fusing Statistical and Deep Learning Models
https://www.mdpi.com/1424-8220/19/11/2451/htm
摘要
对流数据的异常检测十分重要。一般的流数据异常检测方法使用基于统计的技术( statistical anomaly detection technique)和基于深度学习的技术(deep learning-based techniques)。本文提出FuseAD,用残差的方式将两种技术结合在一起,在公开数据集(Yahoo Webscope benchmark)上测试时AUC比其他的异常检测方法更好。本文还通过消融对比研究(an ablation study)量化了两部分各自的贡献。
Introduction
对流数据的异常检测十分重要。。。
异常以及异常检测的定义为:。。。,现在有许多异常检测的方法,有基于统计的,由基于深度学习的,它们分别对特定的流数据有着很好的异常检测效果,两种技术的选择要基于用例以及数据类型。统计方法多用于实际工业中,深度学习方法多用于研究中。
本文主要提出FuseAD方法,结合两种技术,并改善了流程。本文主要贡献如下:
- 结合两种技术。不同于基于集成的异常检测选择不同预测结果中误差最小的一个,我们提出的残差方法(residual scheme)能基于两种技术学习如何产生更好的预测。另外,融合机制(the fusion mechanism )使网络可以通过融合封装在其中的信息来补充底层两个不相交模型的优势。结果,在其中单个模型无法产生良好结果的情况下,这种融合网络的性能更好。
- 广泛评估了许多不同的基于距离,基于机器学习和基于深度学习的异常检测方法。包括iForest,一类支持向量机(OCSVM),局部离群因子(LOF),主要成分分析(PCA),TwitterAD ,DeepAnT,贝叶斯ChangePT,Context OSE ,EXPOSE,HTM Java,NUMENTA ,相对熵,skyline,Twitter ADVec和 Windowed Gaussian。我们在两个共包含423时间序列的数据异常检测的基准(benchmark)上进行评估。
- 消融研究(An ablation study)来确定不同组成部分的贡献。我们通过将融合模型的结果与每个单独的模型进行比较来强调使用融合模型的重要性。
本文的其余部分的结构:第2节以传统和基于深度学习的异常检测为方向概述了先前的工作。第3节中提供了提案手法(FuseAD)的详细信息。在第4节中定义了实验。在第5节中比较并讨论了获得的结果。第6节在FuseAD上进行消融研究。最后,第7节总结了本文。
Literature Review 文献综述
本文重点介绍对传感器数据的异常检测方法及其分类。
- 所用模型的类型:线性模型,统计模型,概率模型,基于聚类,基于最近邻居,基于密度和基于深度学习等。
- 应用程序:欺诈检测,监视,工业损坏检测,医疗异常检测和入侵检测等。
基于距离的异常检测:k-NN
基于密度的异常检测:local outlier factor (LOF), 及其变种connectivity-based outlier factor (COF)和influenced outlierness (INFLO)
网络入侵检测系统(??什么鬼)
一般的流数据异常检测用统计模型ARIMA等预测数据并与真实数据比较
基于神经网络的异常检测:LSTM,CNN(多元时间序列预测),DeepAnt(网络监控领域)
Buda et al. (2018) [29] 使用不同的LSTM模型和统计模型一起预测,并选择training set中均方误差最小的预测器,每个预测器是互相独立的。但是本文中提出的手法FuseAD能学习生成最好的结果。
Methodology 方法论
FuseAD方法结合ARIMA模型以及CNN模型来预测下一时刻的值。并将预测值传给异常检测模块判断是否为异常。
ARIMA模型:非季节性ARIMA模型表示为ARIMA(p,d,q),其中p,d和q是非负整数参数。滞后阶数(Lag order)(p)是模型中包含的滞后观测值的数量,差异度(the degree of differencing)(d)是使序列平稳所需的非季节性差异的数量,移动平均窗口大小( the moving average window size)(q)是滞后的数量预测中的预测错误。
CNN在很多异常检测场景下好于其他NN,损失函数是mean absolute error (MAE) 平均绝对误差,原因:使用最少的参数来保持体系结构的简单,以确保可以使用非常有限的数据量将网络成功地约束为合理的解决方案,这是公开可用的时间序列数据集的常见情况。(We keep the architecture simple with a minimal number of parameters in order to make sure that the network can be successfully constrained to a reasonable solution with a very limited amount of data, which is a common case in publicly available time-series datasets. )
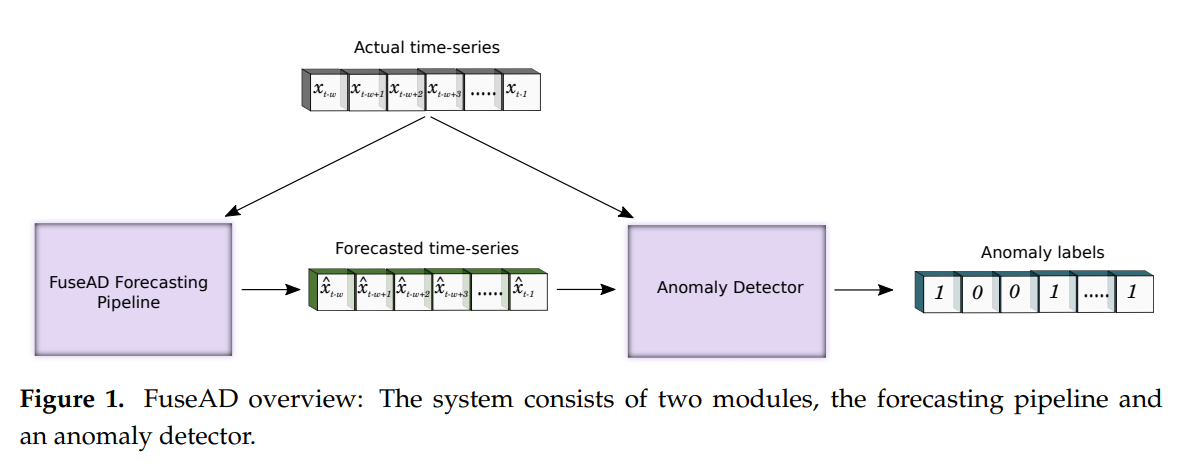
提案方法 FuseAD
FuseAD由两部分组成,预测模块和异常检测模块。
预测模块
在预测模块中,我们将基于统计的模型和基于深度学习的模型组合成一个新颖的残差学习方案。
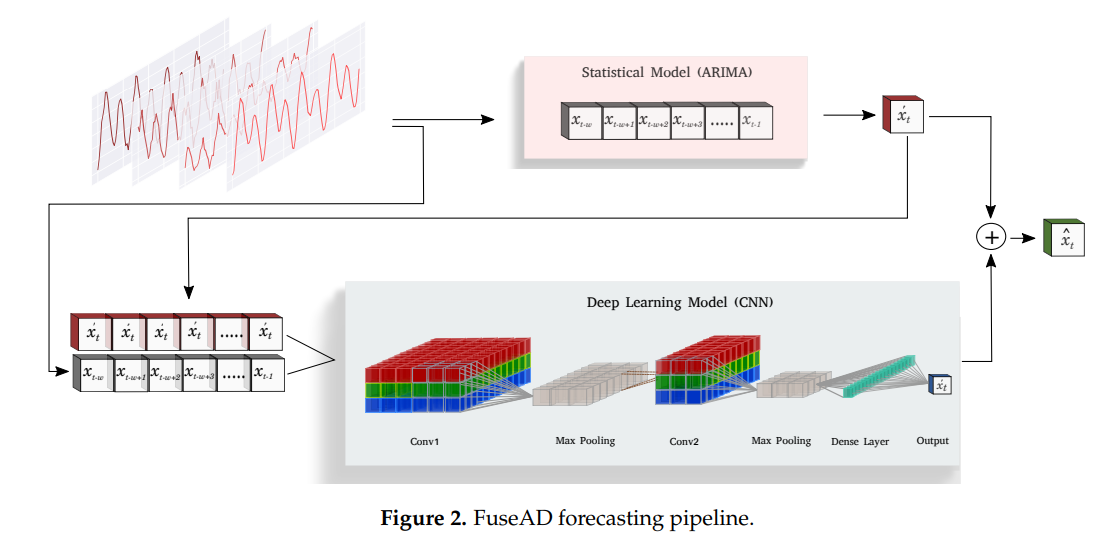
如图所示,原数据$x_{t-w},...,x_t$先由统计模型ARIMA预测下一时刻的值$x_t'$,再将原数据$x_{t-w},...,x_t$与ARIMA预测值一起$x_t'$输入CNN,生成中间量作为对ARIMA预测值的补充,将两者之和作为输出成为整个预测模型的预测值。
因此,在ARIMA的输出准确的情况下,CNN可以抑制其输出,以保留ARIMA做出的预测。另一方面,当ARIMA预测显著偏离时,网络可以生成较大的偏移量,以补偿ARIMA模型造成的误差。这样,网络本身可以在训练过程中决定对ARIMA输出的依赖,以适应其行为,从而克服其局限性。
公式可以写为
$$\hat x_t = \Phi([x_{t-w}, ...,x_{t-1};x_t']) + x_t' $$
其中$x_t'$表示ARIMA模型预测值,$\Phi([x_{t-w}, ...,x_{t-1};x_t'])$表示CNN输出的补充偏移量。
当然,也有更多其它策略来使用CNN输出的中间层和统计模型的预测值,在本文中直接将两者相加,即CNN输出值作为补充偏移量。
异常检测模块
在异常检测模块中,我们直接使用预测值与真实值的欧氏距离作为异常得分,得分大于一定阈值则标记为异常。
实验
在两个公开流数据数据集基准上对比了FuseAD和其他异常检测方法。
Yahoo Webscope Dataset 和 NAB Dataset,都是40%数据用于训练,60%数据用于测试
评估方法:AUC:ROC曲线下的面积,越接近1越好。
实验结果:在Yahoo Webscope Dataset中,FuseAD的性能优于其他方法。在 NAB Dataset中,大家差不多,理由是数据集不好(。。。)
ablation study 消融研究
我们对FuseAD框架进行了消融研究,以便确定整个流程中不同组件的贡献。
单独模型预测AUC没有结合模型好。在一段单独的时间序列中,F-score也是结合模型比较好。
总结
(都是废话)